2021-0329-NETPLIER
NETPLIER: Probabilistic Network Protocol Reverse Engineering from Message Traces
作者:Yapeng Ye, Zhuo Zhang, Fei Wang, Xiangyu Zhang, Dongyan Xu
单位:Department of Computer Science, Purdue University
会议:NDSS 2021
论文链接:https://www.ndss-symposium.org/wp-content/uploads/ndss2021_4A-5_24531_paper.pdf
Abstract
网络协议逆向在很多安全研究领域都有着重要作用。在无法获取到程序的二进制文件的情况下,自动化分析协议字段主要是通过对message trace进行分析,从而推断出协议的格式。主要有pair-wise sequence alignment和tokenization两种主要方式。但两种方式对数量较多的消息进行分析时效果不佳。作者提出了一种基于概率的针对network message trace的协议逆向方法。并通过对10种协议进行分析,表面作者的方案优于现有的逆向技术。
Introduction
许多应用程序中都包含私有协议,例如自动驾驶汽车中使用了CAN总线和FlexRay、工业控制系统中常用的Modbus和DNP3、在线聊天、会议软件也通常会使用其私有协议。许多安全分析,例如漏洞扫描、fuzzing、恶意软件行为分析,都需要对所使用到的网络协议进行精确建模。
目前的协议逆向技术主要有使用基于程序分析、基于trace分析的两种主要方式。基于程序分析的方式,具有较高的准确度,这些基于程序分析的逆向技术都需要程序的二进制文件。然而在很多情况下,程序的二进制文件是很难获取的,例如部分IoT设备中使用了部分保护机制,使得其二进制文件被加密压缩或混淆;只能够获得客户端程序而很难获得服务端程序。因此,先前有许多工作是基于trace分析进行网络协议逆向的技术,其主要分为两类:alignment based和token based。但作者发现这些技术都基于一个假设:如果消息具有相似的值或模式,则属于同一种类型,在遇到较为复杂的情况时会产生大量错误聚类。
但是在实际中,客户端或服务器收到消息时仅通过消息中的某一个字段(keyword)来确定消息类型,如果能改确定表示keyword的字段,则能够得到理想的聚类结果。因此作者提出了一种基于概率的网络协议逆向技术。通过对来自客户端和服务器端的消息配对并使用生物学中常用的多重序列对齐算法(MSA)算法将消息划分为字段列表,对每个字段引入一个变量表示其成为关键字的可能性。对每一个字段假设其为关键字,根据其进行分组,并计算一系列的约束条件,得到该变量成为关键字的后验概率,选取后验概率最高的字段作为关键字,使用它对消息进行聚类。
作者的贡献如下:
- 指出了网络协议逆向分析中的一个关键挑战:keyword识别
- 将keyword识别转化为一个概率问题
- 实现了prototype NETPLIER,输入network trace,输出协议的格式
- 使用NETPLIER对10种协议进行了测试,NETPLIER达到了100% homogeneity,97.9% completeness。并对两个realworld case(Google Nest,a recent malware)进行了分析。
Motivation
Motivation Example
keyword的定义:用于标示消息类型的字段。
Distributed Network Protocol 3 (DNP3)
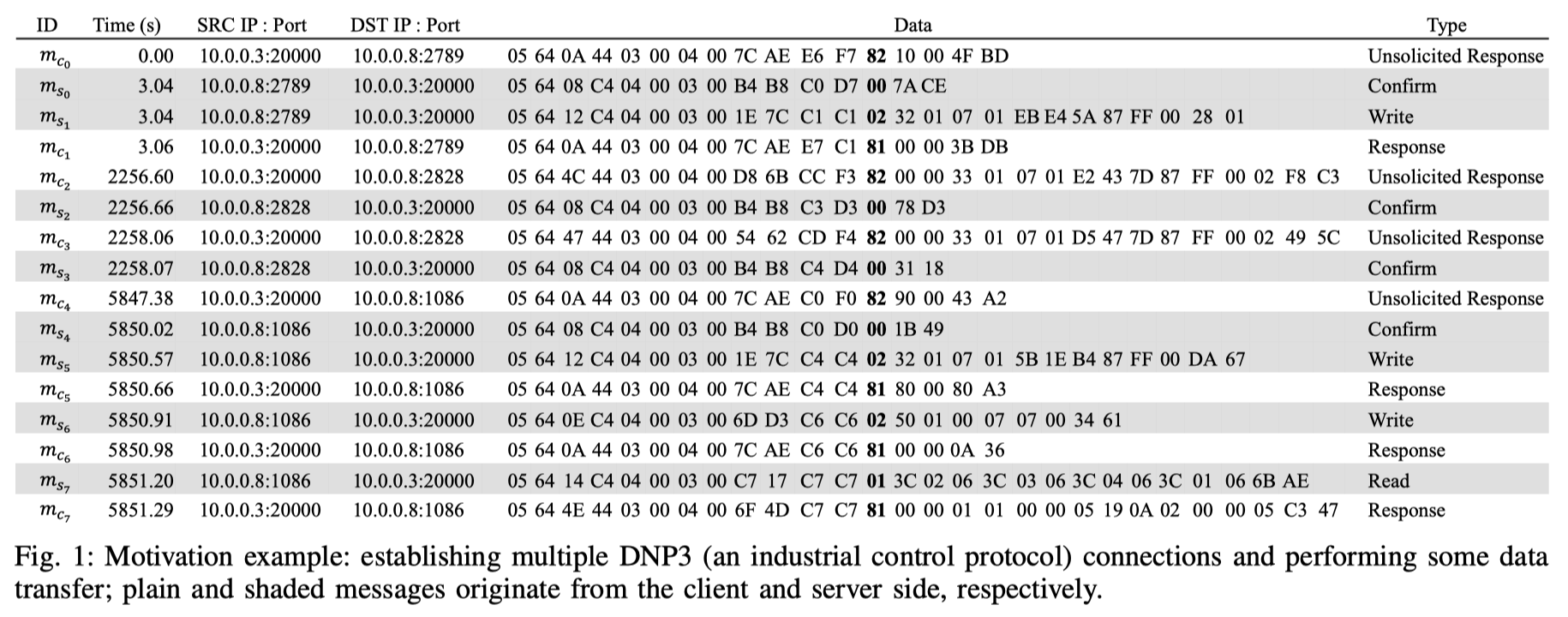
Alignment-based Clustering
序列对齐算法,最初是用于生物学中对DNA、RNA进行排列以识别相似序列的方法。
目前的Alignment-based方法主要是使用序列对齐算法对比每一对消息并计算相似性分数,构造相似度矩阵,再对相似度最高的消息/cluster进行递归聚类。最后得到协议格式和状态机。
局限性:
- 假设消息具有相同的类型,不同类型的消息可能会有部分字段相同的字段并有相同的值,如下图(a)
- 在聚类时需要一个相似性阈值。然而在对未知协议进行逆向时,由于缺少ground truth,很难得到最佳的阈值。
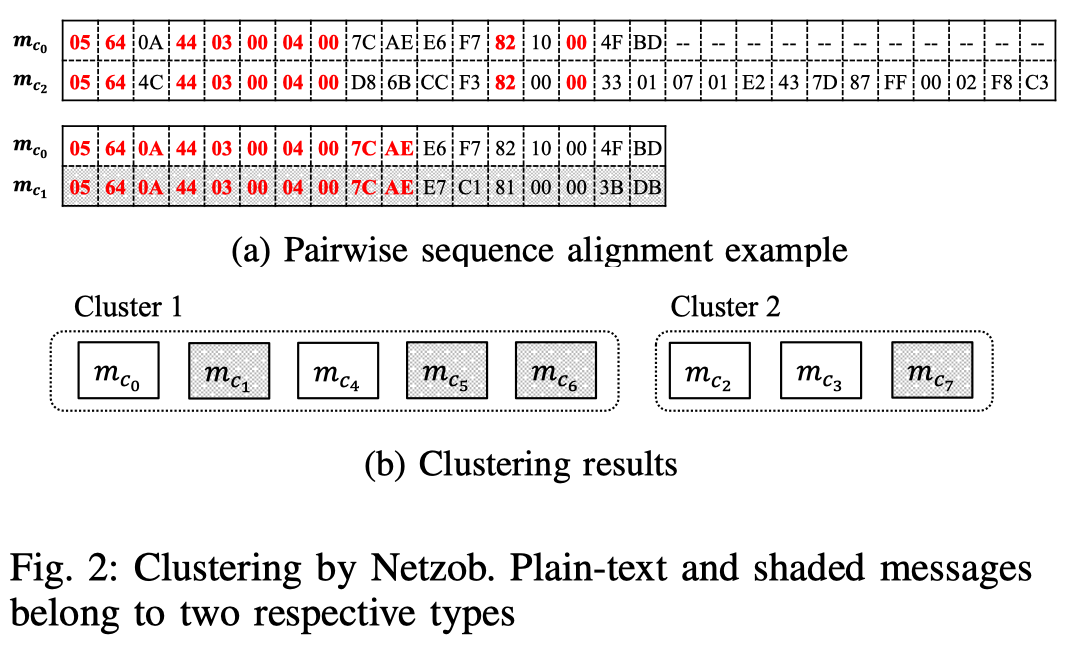
Token-based Clustering
Token-based Clustering的方法依靠先将消息拆分为token,再根据token的值和类型进行聚类。但是这种方法严重依赖token之间的分隔符,对于有明显分隔符的协议如HTTP能够取得较好的效果。然而对于无分隔符的二进制协议,由于缺乏分隔符,大多数字节被视为单独的token,也有一些连续的ascii字符被误认为是token。
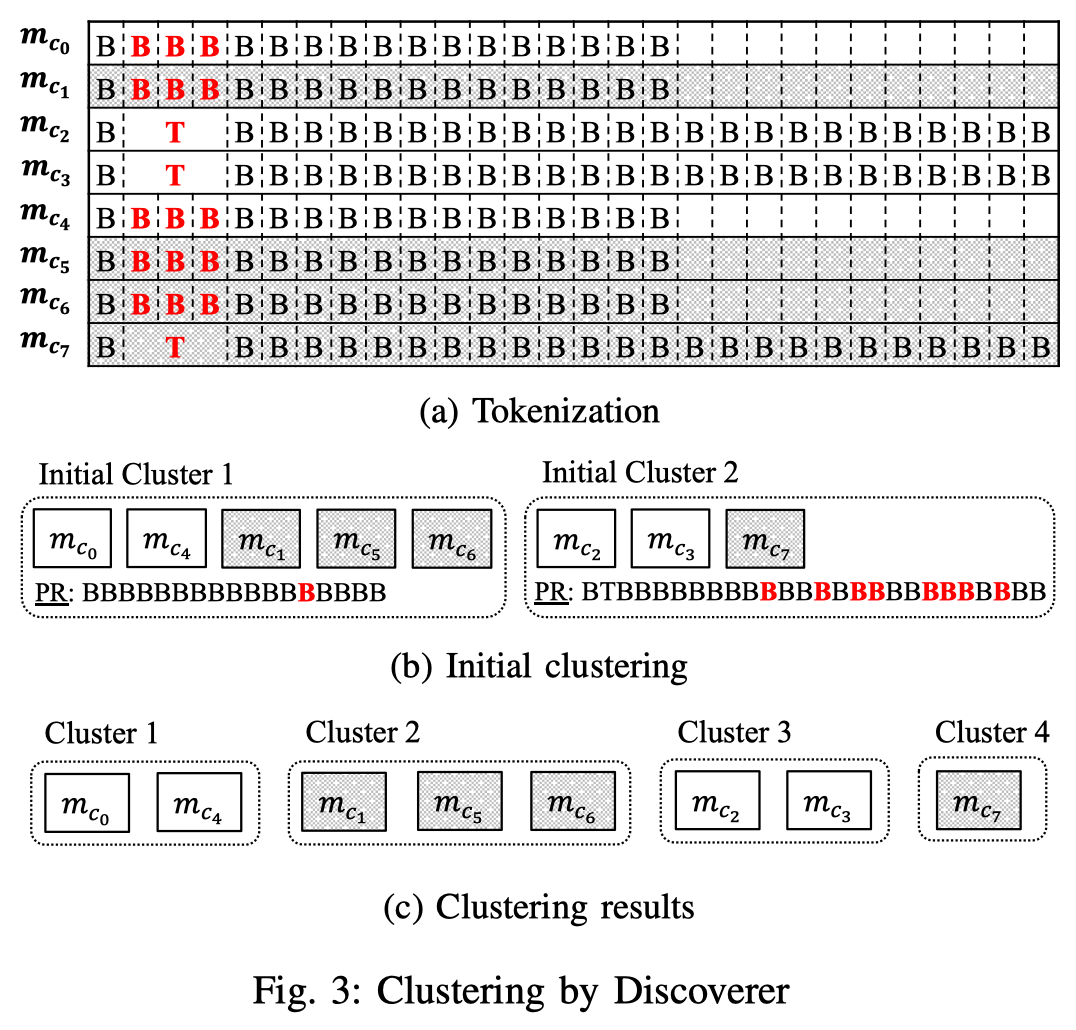
NETPLIER Technique
Insights
- message的类型仅由其中的一个字段决定,keyword
- 之前的方法仅分析client side或server side的message,作者发现可以通过观察client side和server side message的因果关系来辅助分析。如Write message会触发Response message
基于这些观察,作者的想法是:先通过multiple sequence alignment (MSA)算法将消息划分为字段。对于每个字段,用一个变量表示其成为keyword的可能性,并假设其为keyword,计算此时消息序列的一系列约束条件的满足程度(message similarity constraints, remote coupling constraints, structure coherence constraints, and dimension constraints),得到每个字段成为keyword的后验概率。选择后验概率最高的字段为keyword字段,并按照keyword字段进行聚类。
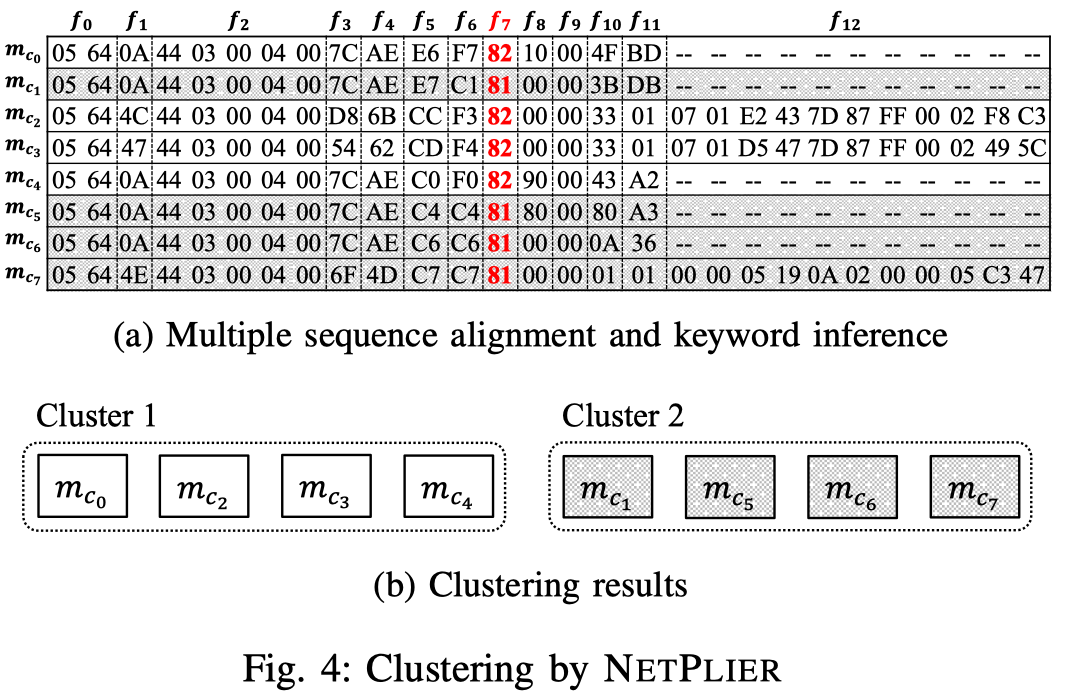
Design
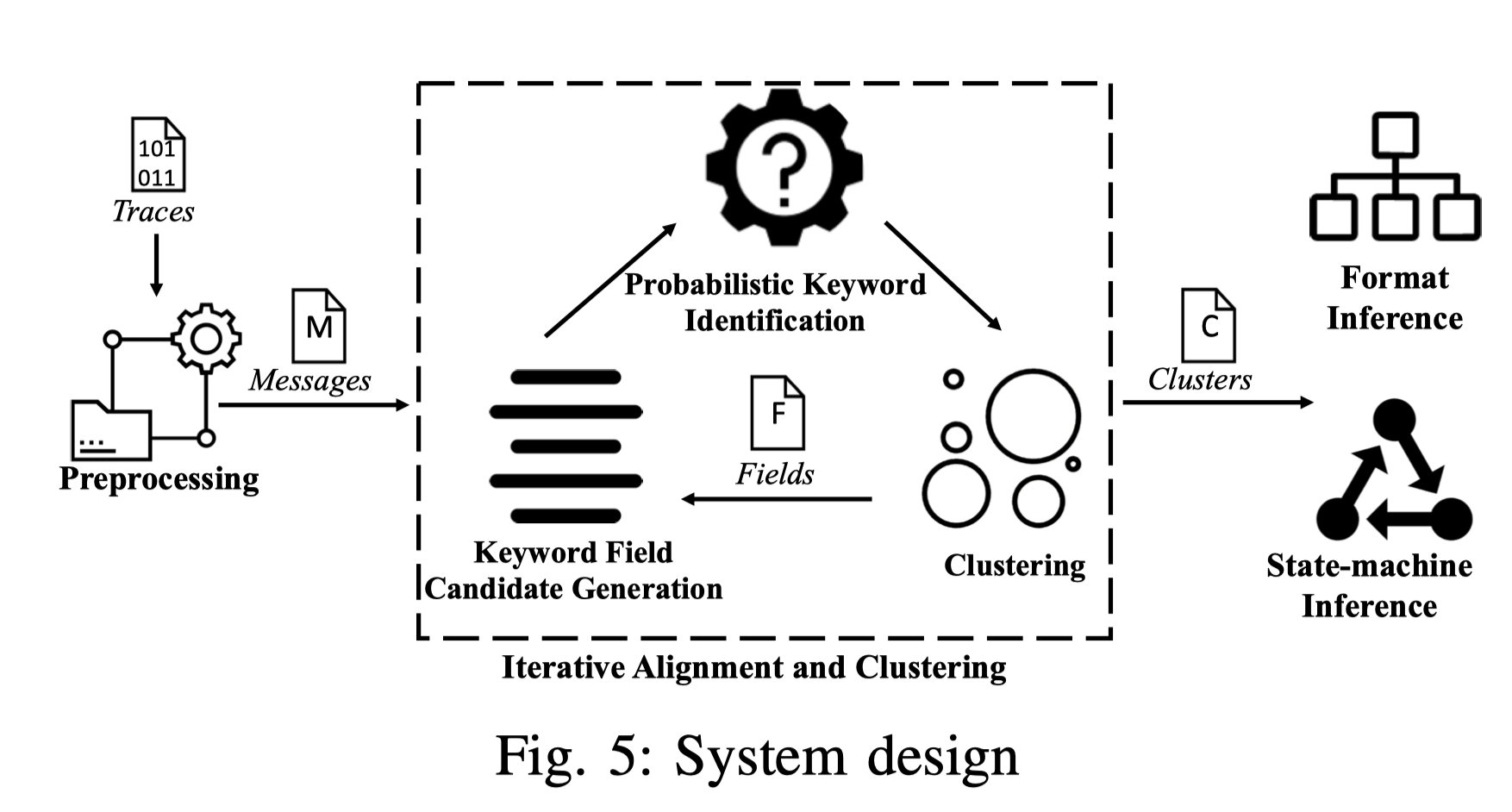
- Preprocessing,通过tcpdump等工具进行抓包,并提取关键字段:时间戳、IP地址、端口号即数据。
- Keyword Field Candidate Generation,划分字段,确定一组可以作为keyword的字段
- Probabilistic Keyword Identification,推断最有可能是keyword的字段
- Iterative Alignment and Clustering,在每个簇内进行迭代,以缓解MSA对齐算法的不确定性,找到最合适的keyword
- Format and State Machine Inference
Keyword Field Candidate Generation
主要解决的两个问题:
- 变长字段的对齐
- 一次性对比所有序列,而不需要两两比较
作者使用生物信息学中的multiple sequence alignment (MSA)算法一次性对比所有序列,以减少计算复杂性。并使用了渐进和迭代的方法,以提高准确性。
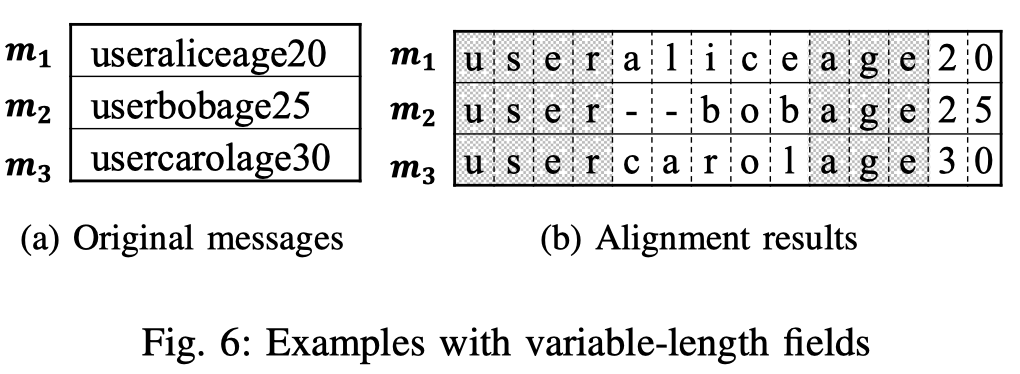
由于MSA对齐得到的结果可能不准确,作者较为保守的使用对齐结果。作者将对齐的每个字节视为独立的字段,并分为静态(该字段在所有消息中值相同)和动态字段。随后对静态字段进行合并。
排除掉在部分消息中缺省的字段,剩下的为keyword候选字段。
Probabilistic Keyword Identification
对每个字段,假设其为keyword进行聚类,观察其是否符合keyword的条件。作者提出了以下四点Observation:
- 同一个cluster中的消息应该比不同cluster中的消息更相似
- 客户端和服务器的cluster应该具有对应关系
- 同一cluster中的消息遵循相同的字段结构
- cluster的数量不应该过多,对于各个cluster中的消息数量不应该过少
作者按照这四点Observations设置了四个Constraints,用于评价该字段成为keyword的可能性。
Message Similarity Constraints,计算每条消息与同cluster和不同cluster消息的相似度
Remote Coupling Constraints,计算一个簇其对应的client侧/server侧对应消息簇的数量

Structure Coherence Constraints,选取keyword后,对簇内message再次进行对齐,计算alignment gaps的数量。如果字段结构不同会存在较大的alignment gaps。
Dimension Constraints
Normalization,将上述四点得到的概率值归一化。
选择后验概率最大的keyword的聚类结果。
Iterative Alignment and Clustering
在每个簇内进行迭代,以缓解MSA对齐算法的不确定性,找到最好的keyword
Format and State Machine Inference
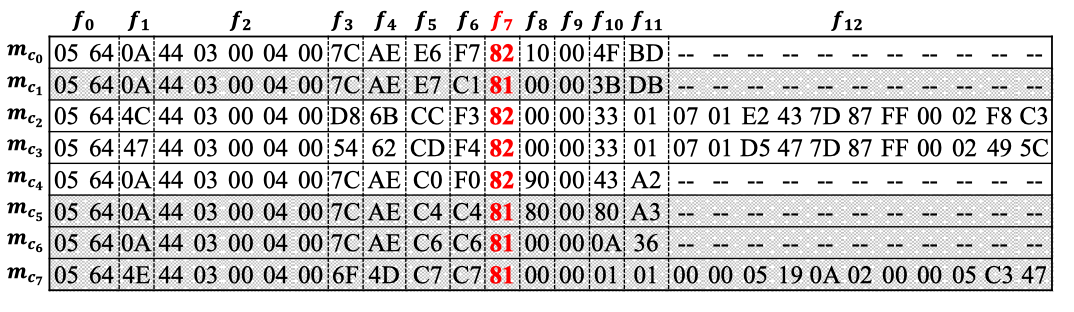
Format:length (L), value (V ), and field type (S: static field; D: dynamic field)
- f0 S(V = ‘0564’)
- f7 D(L = 1, V = [‘82’, ‘81’])
- f12 D(L=(0, 11))
Evaluation
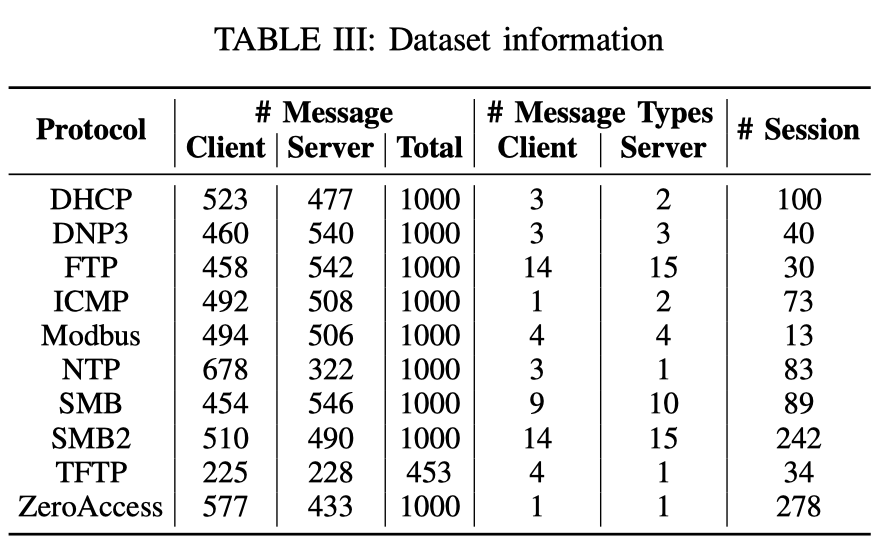
Dataset:十个公开协议
评估指标:
- homogeneity:每个cluster仅包含一种类型的message
- completeness:对于给定类型的message被分配给同一cluster
作者将NETPLIER与其他两个基于trace分析的协议逆向技术(Netzob、Discoverer)进行对比,识别的准确度远高于Netzob和Discoverer。
Results of Different Protocols & Datasets of Different Sizes
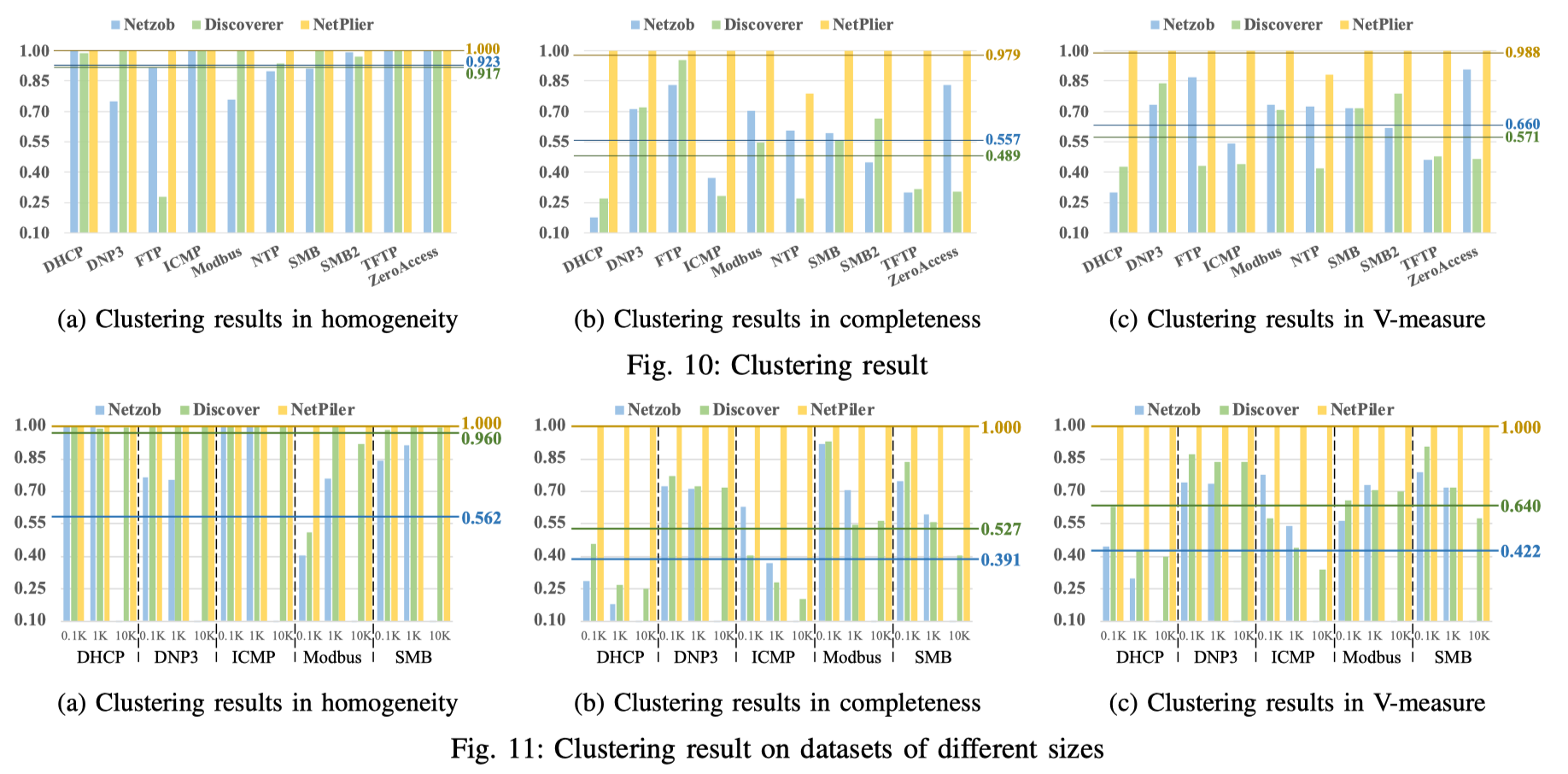
NTP中仅使用几个bit表示消息类型,而NetPlier的最小单位为字节。
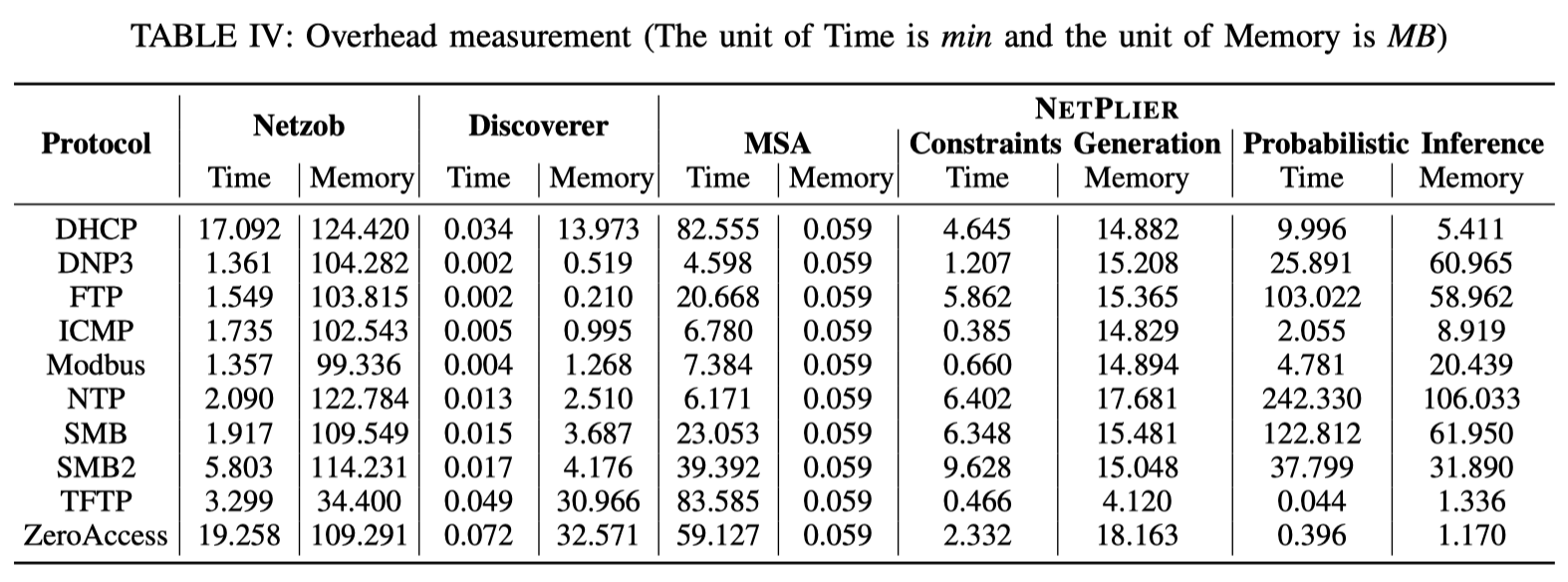
分析所需的开销:(32-cores CPU, 128G memory)
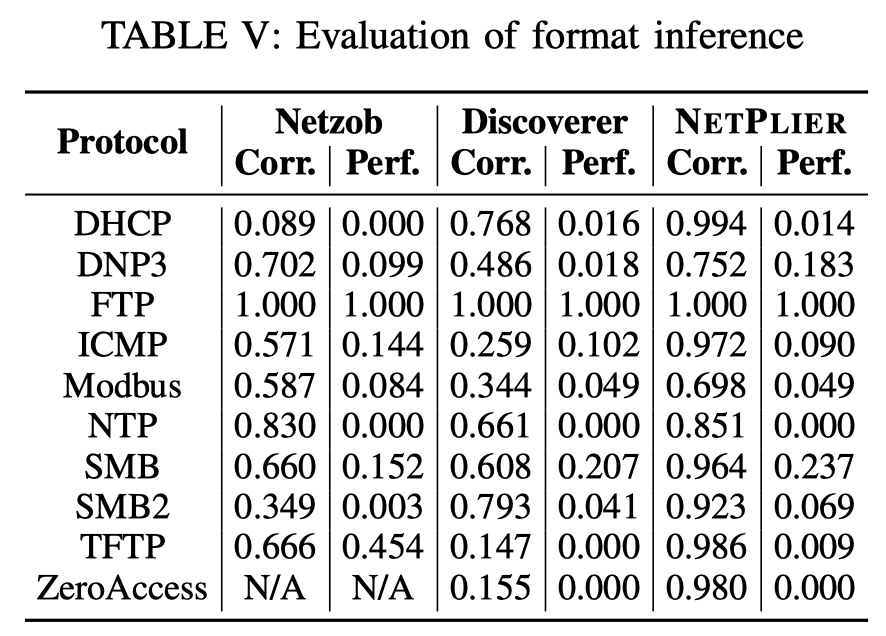
Evaluation of Format Inference
correct(推断出的field位于真正的field内) & accurate(field完美匹配)
Application
IoT Protocol Reverse engineering
作者针对Google的一款恒温器的流量进行分析,分析出协议的格式,并能够构造报文控制其设定温度。

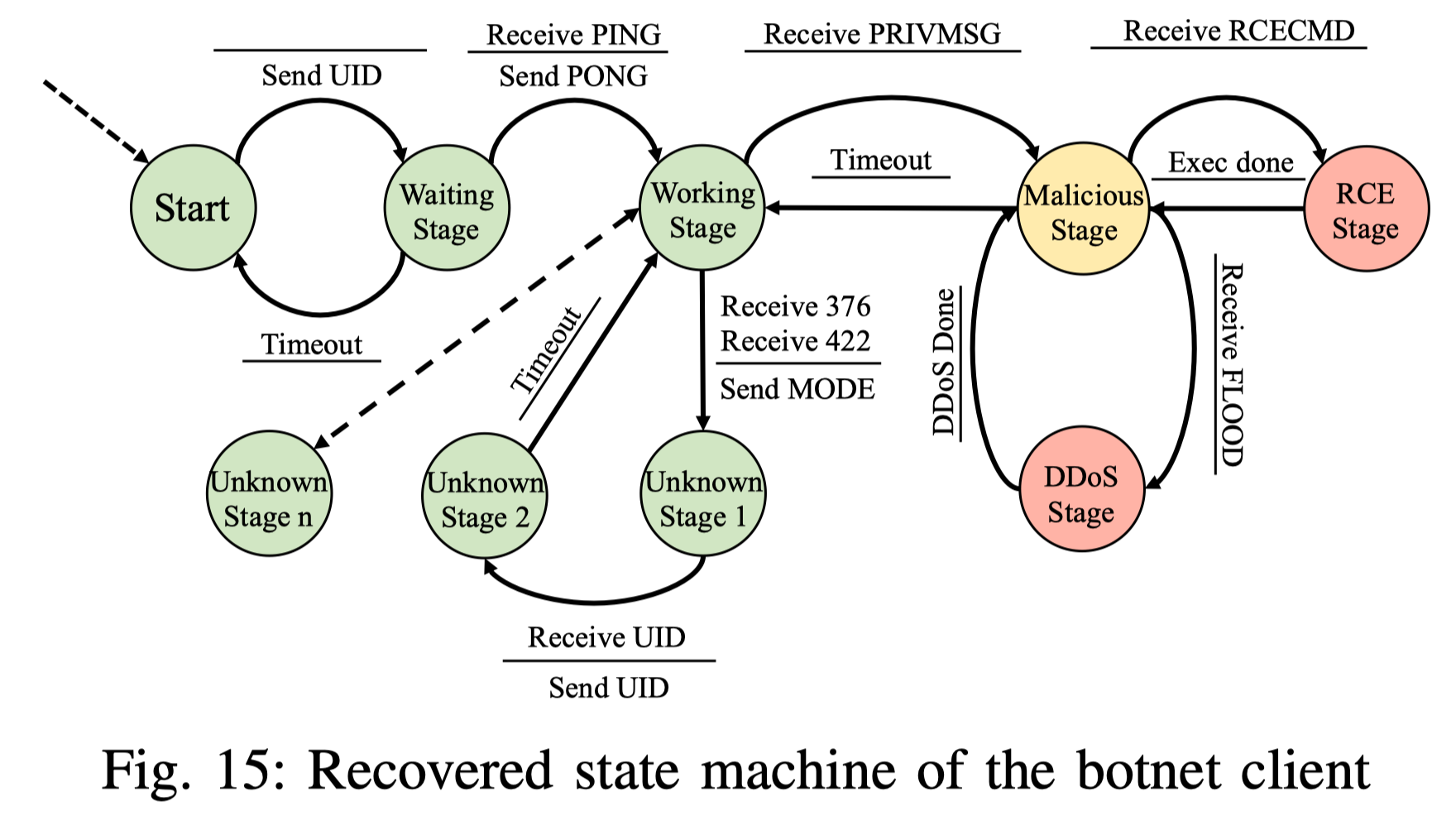
Malware Analysis
恶意软件状态机推断
作者分析了一个僵尸网络客户端程序,对其与C&C通信的状态机进行了分析。
Conclusion
作者提出了一种基于概率的协议逆向技术,通过对message trace进行分析,引入随机变量来表示各自字段成为keyword的可能性,计算这些随机变量各个约束条件的联合概率,最后选择后验概率最大的字段作为keyword,使得NetPlier可以准确识别各种类型的消息,结果远优于Netzob和Discoverer。